







August 02, 2023 – OpenAI and Meta, among other prominent companies, have recently come under scrutiny for their use of the term “open-source” in relation to their language models. Researchers from the University of Nijmegen in the Netherlands released a thought-provoking study pointing out that some language models labeled as “open-source” are not truly open to the public.

The study specifically mentions Meta’s Llama 2 model and OpenAI’s GPT/codex models, stating that the code used to train these language models is not readily accessible to researchers and developers. This lack of transparency raises concerns within the AI community, as the issue of limited access to open-source language models becomes increasingly prominent.
The research team is urging companies to release more genuinely open Large Language Models (LLMs) to foster collaboration and improve performance. With the current landscape, developers and researchers face inherent disadvantages when working with non-open models, hindering their ability to replicate findings or enhance existing language models.
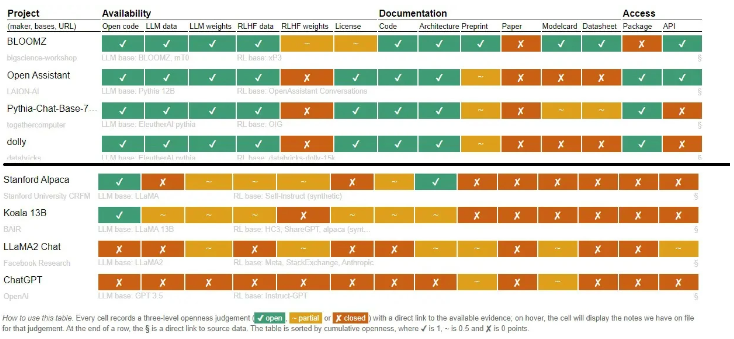
Companies’ motivations for limited openness appear multifaceted, including a desire to safeguard intellectual property and maintain control over the use of their models. However, this practice inadvertently hampers progress in the field, potentially stifling innovation and collaboration.
Meta’s stance on Llama 2 is seen as ironic, touting its availability for research while withholding certain aspects from external developers and researchers. OpenAI’s ChatGPT model also comes under scrutiny as one of the most enigmatic models, not aligning fully with open-source standards.
The study’s conclusion underscores the importance of fostering a culture of openness within the AI community. While protecting intellectual property is crucial, greater accessibility to language models encourages diversity in research and innovation, ultimately driving advancements in the field of artificial intelligence.



