







February 18, 2024 – Amazon’s artificial intelligence research team has announced the development of what is claimed to be the largest text-to-speech model ever created, boasting the highest number of parameters and utilizing the most extensive training dataset to date. Details of the model’s development and training process have been outlined in a paper published on the arXiv preprint server.
In recent years, “large language models” like ChatGPT have garnered significant attention for their ability to intelligently answer questions and generate advanced text. However, artificial intelligence is also making its way into other mainstream applications. In this new project, researchers sought to enhance the capabilities of text-to-speech applications by increasing the number of parameters and expanding the training dataset.
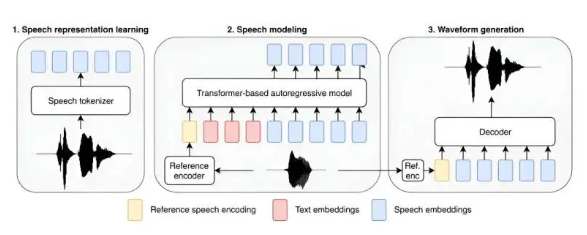
The new model, named “BASE TTS” (Scalable Streaming Text-to-Speech Model), boasts an impressive 980 million parameters and was trained using 100,000 hours of audio recordings sourced from public websites, predominantly in English. Additionally, the researchers provided the model with examples of words and phrases in other languages, enabling it to pronounce common expressions such as “au contraire” and “adios, amigo” correctly.
The Amazon team also experimented with models trained on smaller datasets, hoping to uncover what is known in the field of artificial intelligence as “emergent abilities.” These abilities refer to the sudden leap in intelligence exhibited by AI applications, whether they are large language models or text-to-speech models. Their findings revealed that for text-to-speech applications, this jump in performance occurs with a medium-sized dataset of around 150 million parameters.
The researchers further noted that this leap involves various linguistic attributes, such as the ability to use compound nouns, express emotions, utilize foreign words, apply phonology and punctuation, and correctly emphasize key words in a sentence.
Citing concerns over potential misuse, the research team has stated that BASE TTS will not be made available to the public. Instead, they plan to use it as a learning application and apply the knowledge gained to improve the overall sound quality of text-to-speech applications.



